
Introdução a Linguagem SQL — Parte 1
- Tempo de Leitura: 7 minutos

Neste artigo, falarei sobre a linguagem de consulta estruturada (SQL na sigla em inglês) e como ela processa e armazena informações em bancos de dados relacionais. Possivelmente, dividirei o artigo em algumas partes para que a leitura não fique extensa e se torne mais agradável ao leitor.
Antes de iniciar diretamente na linguagem SQL, são necessários alguns conceitos importantes sobre bancos de dados.
Conceitos…
A linguagem de programação SQL, como já citada anteriormente, é utilizada no processamento e armazenamento de informações em bancos de dados relacionais. Mas afinal de contas, o que é um banco de dados relacional? E antes disso, o que é um banco de dados?
Banco de Dados (BD)
Nos dias atuais, é quase impossível imaginar uma aplicação computacional (e aqui incluo também apps para smartphones) sem associar a algum banco de dados. Desde um sistema que gerencie o estoque de um supermercado, até uma simples agenda telefônica armazenada em um smartphone, salvo raras exceções, um banco de dados estará ligado a aplicação ou software em questão.
Mas e aí? O que é um banco de dados? De acordo com ELMASRI E NAVATHE (2009):
“Um banco de dados é uma coleção de dados relacionados. Os dados são fatos que podem ser gravados e que possuem um significado implícito. Por exemplo, considere nomes, números telefônicos e endereços de pessoas que você conhece. Esses dados podem ter sido escritos em uma agenda de telefones ou armazenados em um computador, por meio de programas como Microsoft Access ou Excel. Essas informações são uma coleção de dados com um significado implícito, consequentemente, um banco de dados.”
Em outras palavras, um banco de dados possui algumas fontes das quais os dados são derivados e algum nível de interação com eventos do mundo real e um público que tenha interesse em seu conteúdo.
É importante ressaltar que, um banco de dados pode ser gerado e mantido manualmente ou de forma automatizada. O exemplo citado por ELMASRI e NAVATHE (2009) e que trasncrevi alguns parágratos acima, retrata de forma prática esse processo automatizado versus processo manual. Uma agenda com nomes, números de telefones e endereços pode ser gerada e mantida em um bloco de papel ou pode ser gerada e mantida de forma automatizada por um sistema de computador (software) para este fim. Obviamente, neste artigo e nos próximos estaremos concentrados nos processos de geração e manutenção automatizadas de bancos de dados.
Atualmente, existem diversos sistemas gerenciadores de bancos de dados (SGBD) e, também diversos modelos para armazenamento dos dados.
Alguns modelos de armazenamento de dados disponíveis são:
- Relacional
- Entidade/Relacionamento
- Orientado a objetos
- Objeto/Relacional
- No SQL
De volta ao tema principal deste artigo, focaremos nos SGBD’s pertencentes aos grupos relacional e entidade/relacionamento. E, a partir desta afirmação, vem nosso próximo conceito: O que é um banco de dados relacional?
Banco de Dados Relacional

O modelo relacional foi introduzido por Ted Codd, da IBM em 1970 em um artigo que imediatamente atraiu a atenção em virtude de sua simplicidade e base matemática. Conforme descrito no livro Sistemas de Banco de Dados (ELMASRI E NAVATHE, 2009):
“O modelo usa o conceito de uma relação matemática — algo como uma tabela de valores — como seu bloco de construção básica e tem sua base teórica na teoria dos conjutos e na lógica de predicados de primeira ordem.”
Um parênteses neste momento para quem descreve como “simples” o modelo proposto por Ted Codd. Aposto que você, caro leitor, deve estar pensando: Por que não prestei mais atenção às aulas de matemática? (risos)
Mas simplificando a idéia de Ted Codd e para não ficarmos presos na teoria e conceitos envolvidos na construção de um banco de dados relacional, tentarei explicar de forma bem prática como funciona este modelo de banco de dados e também quais são os principais componentes envolvidos.
Resumidamente, um banco de dados relacional é composto por tabelas (relação), onde cada linha corresponde a uma tupla (registro) e, cada coluna a um atributo da relação.
Utilizando o exemplo proposto por ELMASRI E NAVATHE (2009), uma agenda pessoal pode ser representada em um banco de dados relacional conforme a Imagem 01 — Representação de uma agenda pessoal.
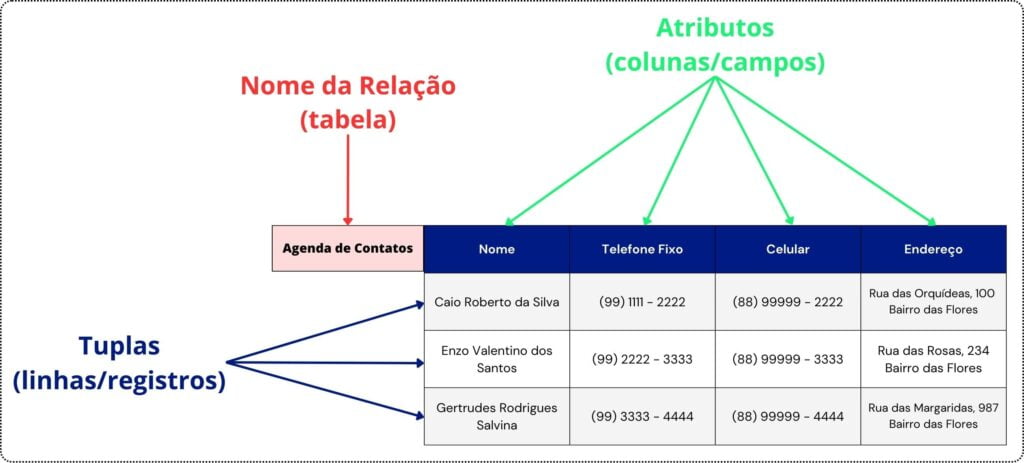
Como representado na Imagem 01, essa tabela apresenta três tuplas (ou três linhas), onde cada uma corresponde aos dados de uma pessoa específica. Também podemos observar que cada linha está dividida em quatro colunas devidamente preenchidas.
As colunas (atributos) são identificadas por um dado específico de cada pessoa: Nome, Telefone Fixo, Celular e Endereço. Por fim, esta tabela (relação) exemplo, está identificada como Agenda de Contatos. Importante destacar que, todos os dados listados pertencem e se relacionam com alguma pessoa específica identificada no atributo “Nome”.
Aproveito para deixar neste momento a primeira dica prática: embora o exemplo apresente o nome da relação (tabela) contendo palavras espaçadas e, nos atributos (campos/colunas) também tenha um caractere especial (no caso do atributo Endereço, a cedilha) e espaçamento entre palavras (Telefone Fixo) não é uma boa prática aplicar isso em um banco de dados que irá para produção.
Mas Paulo, por quê? Fica muito mais fácil e legível. Concordo. Porém, mesmo que, para nós humanos um espaço em branco entre palavras, seja apenas um espaço, para as máquinas, ali existe um caracter de acordo com a tabela ASCII (assunto para outro artigo, caso vejam necessidade, risos) e, nesta mesma tabela, não existe uma representação clara para a cedilha.
Então, neste caso, o melhor é evitar usar espaçamento entre palavras, caracteres especiais e acentos (e aqui, incluimos a cedilha). O principal objetivo é deixar as coisas mais fáceis para o computador e, consequentemente para o humano que for utilizar e manter esse banco de dados depois (risos).
Quando for necessário mais de uma palavra para representar um atributo ou relação, adote a convenção de concatenar as palavras separando por iniciais maiúsculas (Ex.: agendaDeContatos) ou utilizando o caractere underline (Ex.: agenda_de_contatos).
Outra boa prática quanto a definição de nomes para tabelas e atributos é adotar nomenclatura que identifique de forma bem clara os valores que serão armazenados em cada um. Então, a segunda dica prática é, cuidado com a criatividade na hora da criação de tabelas e campos para os bancos de dados que forem trabalhar (risos).
Por exemplo, para identificar um atributo que armazene valor de desconto em uma tabela de produtos, um bom nome para este atributo seria valor_desconto ao invés de utilizar vl_desc, ou vlr_desc ou v_desc.
Evitar abreviaturas que só quem planejou e desenvolveu o banco de dados saberá pra que serve, facilitará no processo de manutenção futura.
Principais SGBD’s Relacionais
Com a evolução do modelo relacional, diversas ferramentas foram desenvolvidas e estão disponíveis. Segue uma lista com os sistemas gerenciadores de banco de dados mais populares linkados aos seus respectivos sites:
Mas não se limite a minha lista e tão pouco a defender que o SGBD “A” é melhor que “B”. Cada um dos sistemas aqui listados tem suas particularidades e ferramentas que melhor resolvem determinados problemas.
E a terceira dica prática deste artigo é: foque sempre em resolver o problema. Independente da ferramenta usada, o foco em tecnologia sempre deve ser resolução de problemas.
Uma pausa para o café (risos)…

Acredito que estes conceitos iniciais sobre bancos de dados relacionais já nos ajudem no que virá a seguir.
Como citado no início deste artigo, vou dividir em algumas partes para que não canse a leitura e, também para faciltar consultas específicas no futuro.
Nos próximos dias, iremos diretamente ao assunto tema do artigo: Linguagem SQL.
Fiquem de olhos nas minhas redes sociais para não perder nenhuma parte.
Fiquem à vontade para enviar mensagens com dúvidas e/ou sugestões. Tentarei responder o mais breve possível.
Até o próximo!
—
Artigo publicado originalmente na plataforma Medium em 6 de abril de 2023. O acesso ao artigo original pode ser realizado aqui.
Referências
Sistemas de banco de dados / Ramez Elmasri e Shamkant B. Navathe, 4ª Edição, 2009, Editora Pearson Addison Wesley;
Sites dos SGBD’s citados no artigo:
- Microsoft SQL Server: https://www.microsoft.com/pt-br/sql-server/sql-server-2022, acessado em 04/04/2023 às 8h18.
- Oracle: https://www.oracle.com/br/database/, acessado em 04/04/2023 às 8h20.
- MySQL Server: https://www.mysql.com/, acessado em 04/04/2023 às 8h22.
- Firebird: https://firebirdsql.org/, acessado em 04/04/2023 às 8h25.
- PostgreSQL: https://www.postgresql.org/, acessado em 04/04/2023 às 8h27.
- SQLite: https://sqlite.org/index.html, acessado em 04/04/2023 às 8h37.

Sobre o autor
Paulo Fernando Abse Benassi é formado em Sistemas de Informação pela Libertas – Faculdades Integradas de São Sebastião do Paraíso/MG. Analista de Sistemas, desenvolvedor web e analista de dados. Trabalha na área de tecnologia desde 2003. Desde o início da carreira, começou a estudar sobre a área tecnológica e nunca mais parou. Em aprendizado contínuo. Clique aqui para analisar os projetos e atividades desempenhadas pelo autor.
Artigos relacionados



Pingback: Introdução a Linguagem SQL — DDL (Parte 3) - ABAS System
Pingback: Introdução à Linguagem SQL - Parte 2 - ABAS System
Pingback: Introdução a Linguagem SQL — DML (Parte 4 — final) - ABAS System