
Introdução a Linguagem SQL — DML (Parte 4 — final)
- Tempo de Leitura: 19 minutos

Chegamos a última parte desta série de artigos sobre Introdução a Linguagem SQL.
Para não ficar por fora de tudo que aconteceu até aqui, acesse as três primeiras partes clicando nos links abaixo:
- Introdução a Linguagem SQL — Parte 1
- Introdução a Linguagem SQL — Parte 2
- Introdução a Linguagem SQL — DDL Parte 3
Nesta quarta e última parte da nossa série de artigos, apresentarei os principais comandos do “sub-grupo” da Linguagem SQL — DML (Data Manipulation Language — Linguagem de Manipulação de Dados).
Recordando o que foi apresentado na parte 3, os comandos do “sub-grupo” DDL são como a “forma do bolo” para receber os dados. São os comandos que após executados definem e estruturam todo o nosso banco de dados.
Já os comandos do “sub-grupo” DML são efetivamente o “bolo” (em uma referência nada convencional — risos). São comandos destinados a inserir, alterar, selecionar e/ou apagar dados nas tabelas. São, como o próprio nome diz, comandos de manipulação de dados.
Os comandos DDL, em grandes companhias, são limitados aos engenheiros de dados e DBA’s (Database Administrator). Por serem comandos que trabalham com a estrutura dos bancos de dados, são mais restritos a esses profissionais.
Já os comandos DML são os comandos destinados aos usuários: programadores, cientistas de dados, analistas de dados etc. Esse “sub-grupo” de comandos é amplamente utilizado (muito mais que os comandos do “sub-grupo” DDL).
Comentários em SQL
Antes de iniciarmos efetivamente com os exemplos e explicações sobre cada comando, vamos aprender como comentar um código SQL.
Um comentário é um texto informado no código de forma delimitada por alguns caracteres especiais que será ignorado pelo interpretador da linguagem.
É muito importante, principalmente aos iniciantes, documentarem o que um trecho de código faz e para isso, utilizamos de comentários da linguagem.
Na SQL é possível incluir comentários conforme o exemplo a seguir:
/*
Isso é um comentário em SQL.
Tudo que for digitado nesta área, será ignorado.
*/
Tudo que estiver entre a barra-asterisco (/*) e o asterisco-barra (*/) será ignorado pelo interpretador de comandos do SGBD. Um comentário pode estar disposto em uma ou várias linhas. Desde que seja delimitado pelos caracteres informados, o interpretador de comandos do banco de dados irá ignorar.
A partir da próxima seção iniciamos com o nosso primeiro comando DML.
Como inserir dados em uma tabela
O primeiro dos comandos DML que vamos utilizar é justamente para inserir dados em uma tabela. Não tem como manipular dados se os mesmos não existirem, não é? (risos)
Para inserir um registro em tabelas, utilizamos o comando DML INSERT. A sintaxe do comando é:
INSERT INTO nome_da_tabela
[(coluna1, coluna2, coluna3, ...)]
VALUES
(valor1, valor2, valor3, ...);
Onde:
nome_da_tabela: é o nome da tabela onde os dados serão inseridos.(coluna1, coluna2, coluna3, ...): é a lista das colunas da tabela que receberão os valores. Se as colunas não forem especificadas, o comando assumirá que serão inseridos valores em todas as colunas da tabela, na ordem em que foram definidas.(valor1, valor2, valor3, ...): é a lista dos valores a serem inseridos nas colunas correspondentes. Os valores devem estar na ordem correspondente às colunas, e cada valor deve estar separado por vírgula.
No artigo anterior (parte 3) criamos a tabela contatos com os campos:
- id: identificador numérico único
- nome: campo do tipo texto destinado a armazenar o nome do contato
- celular: campo do tipo texto destinado a armazenar o número do telefone celular do contato
- data_nascimento: campo do tipo data para receber a data de nascimento do contato
- endereco: campo do tipo texto para receber o endereço do contato
Utilizando a tabela que criamos, o comando para inserir um registro de contato é:
INSERT INTO contatos
(id, nome, celular, data_nascimento, endereco)
VALUES (
1, 'Primeiro contato', '(99)99999-9999', '2000-01-31',
'Rua das Margaridas, 100 - Jardim das Flores'
);
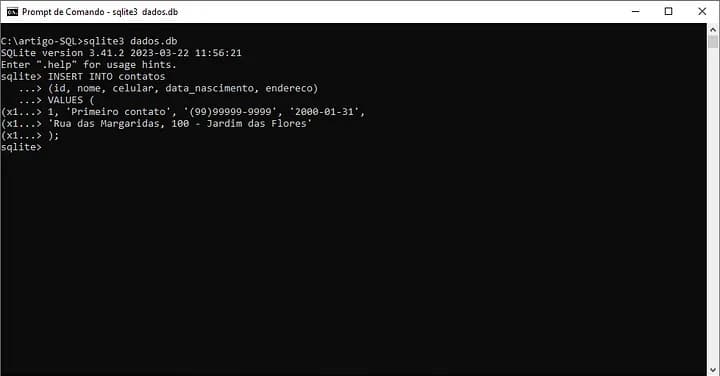
Como a imagem 01 apresenta, após executar o comando não ocorreu nenhum problema.
Alguns detalhes no comando executado merecem atenção:
- Embora eu tenha colocado o nome dos campos após o nome da tabela, esse parâmetro não é obrigatório, pois, em nosso exemplo, foram inseridos após a instrução “VALUES” todos os valores para os campos na ordem exata que estão dispostos na tabela contatos. Caso fosse necessário omitir algum valor (informação não obrigatória, por exemplo) ou, por algum motivo quem criou o comando resolvesse alterar a ordem para passar a informação ao banco de dados, aí sim é obrigatória a inserção do nome dos campos conforme apresentado no exemplo;
- Sempre que for inserir um dado para campos do tipo texto, é obrigatório que o valor esteja entre aspas (podem ser simples, como no exemplo ou duplas). Essa informação pode ser confirmada analisando os valores passados para os campos nome, celular e endereco;
- Para campos do tipo data, além da obrigatoriedade do valor estar entre aspas (semelhante aos valores de texto), é obrigatório analisar o formato aceito pelo banco de dados utilizado. Em nosso exemplo (e na maioria dos SGBD’s atuais), é utilizado o formato baseado no padrão ISO 8601 (“YYYY-MM-DD”), onde: “YYYY” é correspondente ao ano com quatro números (year), “MM” é o mês com dois dígitos (month) e “DD” representa o dia também com dois dígitos (day). Esse formato de data é amplamente utilizado em todo o mundo em diversas aplicações e sistemas, incluindo bancos de dados, linguagens de programação, formulários da web, entre outros;
- Por fim e não menos importante, a forma de digitação segue a mesma dos comandos DDL que apresentei na parte 3 da nossa série de artigos: o comando só será finalizado e executado após a inserção do caractere ponto-e-vírgula (;), portanto, assim como apresentado no exemplo, o comando pode ser digitado em várias linhas ou em uma única.
Inserido o primeiro registro, pode-se optar por inserir outros registros com variações do comando para testes e análise do comportamento do banco.
Deixo aqui, mais dois exemplos de inserção de dados na tabela contatos:
i) omitindo o nome dos campos para inserir um registro na tabela com todos os valores na ordem, e;
ii) deixando de incluir valor em um ou mais campos (omissão de colunas):
/* Comando omitindo nome das colunas,
mas passando valores para todos os campos */
INSERT INTO contatos
VALUES (2, 'Segundo contato', '(88)88888-8888', '1999-12-15',
'Rua das Rosas, 222 - Jardim das Flores');
/* Comando que insere valores apenas em 3 dos campos da tabela contatos */
INSERT INTO contatos (id, nome, endereco)
VALUES (
3, 'Terceiro contato', 'Rua das Hortencias, 333 - Jardim das Flores');
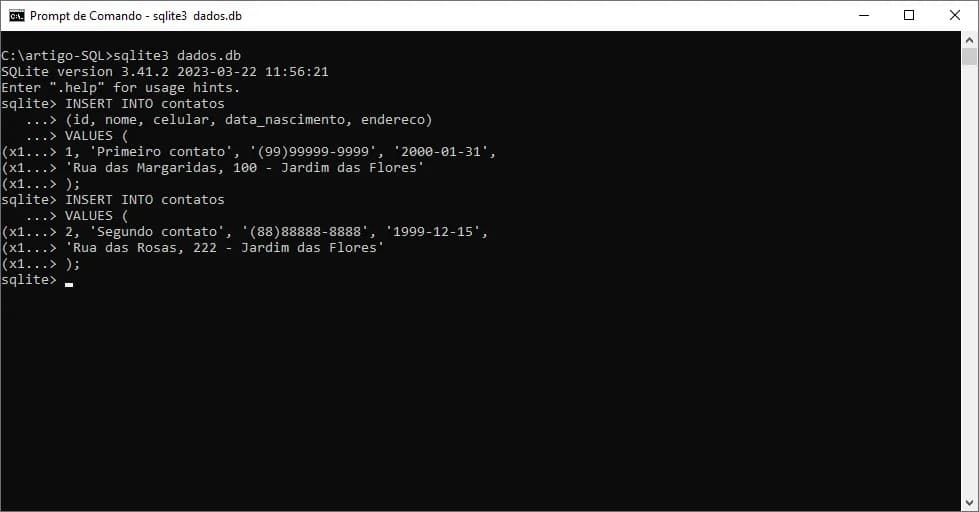
No segundo exemplo, observe que são utilizados apenas três campos (id, nome e endereco) e, os valores devem ser passados na ordem que forem informados os nomes dos campos.
No exemplo, acabei optando pela ordem em que os campos estão dispostos na tabela. Mas nada impede o usuário de utilizar a ordem dos campos que lhe for conveniente.
Só é importante observar que, na mesma ordem que os campos são citados, devem ser passados os valores para não salvar informação trocada ou até gerar algum erro por incompatibilidade de tipo de dados (por exemplo, salvar texto em um campo do tipo numérico).
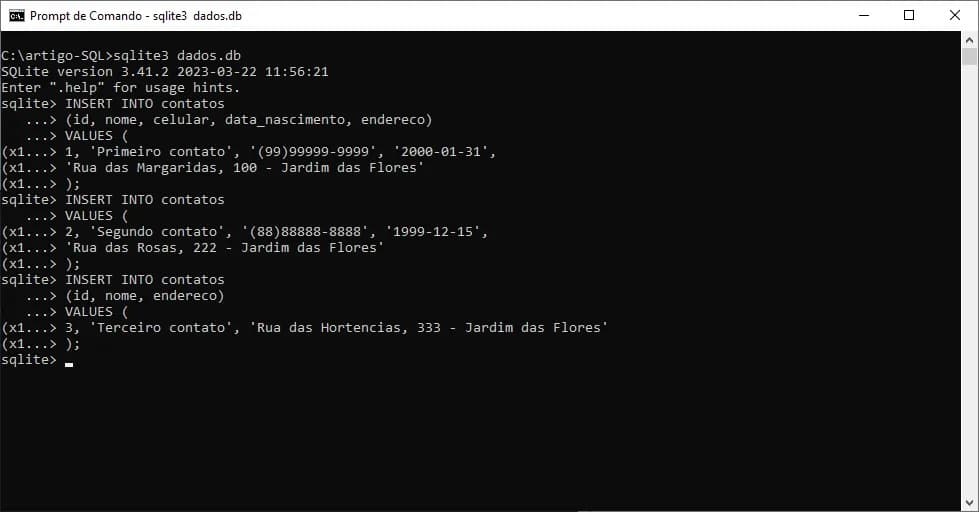
Uma última observação antes de passarmos para os nossos próximos exemplos é com relação ao campo id.
Na definição da estrutura da tabela, marcamos este campo como um tipo especial (PRIMARY KEY). Isso significa que, os valores informados para este campo não podem ser repetidos, pois, como já citado, trata-se de valor para identificação única.
Se por algum motivo, houver a tentativa de duplicar algum valor para este campo, será exibido um erro no prompt de comandos do SQLite (ou de qualquer outro SGBD), conforme apresentado na imagem a seguir:
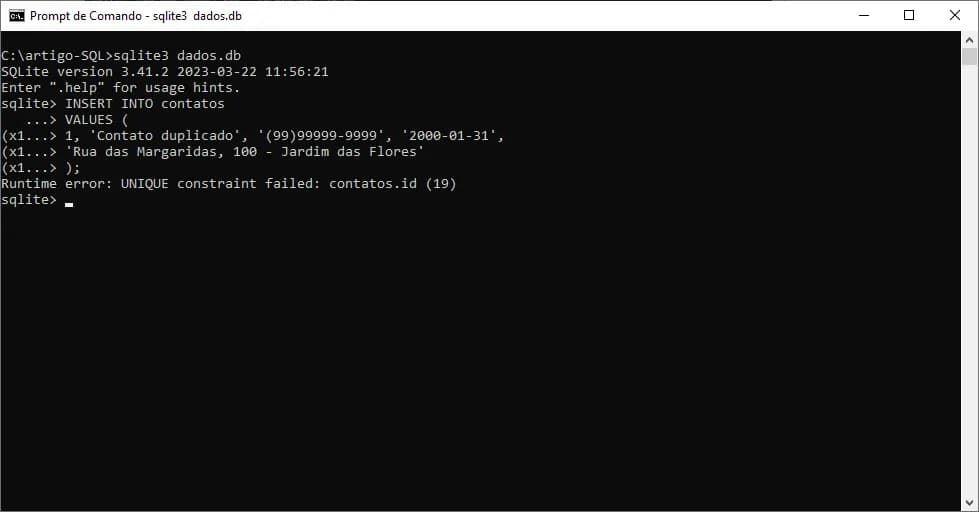
O erro pode ter descrição diferente dependendo do SGBD utilizado. Mas sempre será apresentado como a violação de unicidade do campo.
Você deve estar se perguntando: “Mas e se eu inserir um dado com valor errado? Como fazer a atualização?” Para tanto, existe o comando DML: UPDATE (que exploraremos até o final deste artigo).
O nosso próximo comando DML é justamente para recuperar os valores inseridos no banco de dados. E para tanto, utilizaremos o comando SELECT.
Selecionar registro(s) inserido(s) no banco de dados — Consultas
Para consultar um valor em determinada tabela no banco de dados, utilizamos o comando DML SELECT.
Este comando permite que recuperemos e consultemos valores já inseridos no banco de dados. O resultado, após executar um comando SELECT no banco de dados é uma tabela semelhante a uma planilha de Excel.
A sintaxe básica do comando SELECT é:
SELECT [DISTINCT] column1, column2, ...
FROM table_name
[JOIN table_name ON condition]
WHERE condition
GROUP BY column1, column2, ...
HAVING condition
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
Onde:
SELECT: a palavra-chave que inicia o comando SELECT.[DISTINCT]: opcionalmente, pode ser usado para retornar apenas valores distintos.column1, column2, ...: as colunas que deseja selecionar na tabela.FROM: a palavra-chave que indica a tabela da qual deseja selecionar os dados.table_name: o nome da tabela da qual deseja selecionar os dados.[JOIN table_name ON condition]: opcionalmente, você pode adicionar uma cláusula JOIN para juntar duas ou mais tabelas usando uma condição especificada (assunto que podemos tratar em um artigo específico).WHERE: a palavra-chave que permite filtrar os resultados de acordo com uma ou mais condições.condition: a condição que deseja aplicar para filtrar os resultados.GROUP BY: a palavra-chave que permite agrupar os resultados por uma ou mais colunas.HAVING: a palavra-chave que permite filtrar os resultados após a cláusula GROUP BY ter sido aplicada.ORDER BY: a palavra-chave que permite classificar os resultados em ordem ascendente (ASC) ou descendente (DESC) por uma ou mais colunas.
A quantidade de parâmetros e opções disponíveis no comando SELECT pode assustar o iniciante. Mas dada a semelhança entre a linguagem SQL e o inglês, após dedicar um tempinho analisando o código, fica muito fácil interpretar e entender o que o comando está fazendo.
Vamos ao nosso primeiro exemplo. Digamos que, após inserir vários registros na tabela contatos, você queira recuperar todos os números de telefone celular associando-os a cada nome que pertence. O comando para resolver este nosso problema é o seguinte:
SELECT nome, celular FROM contatos;
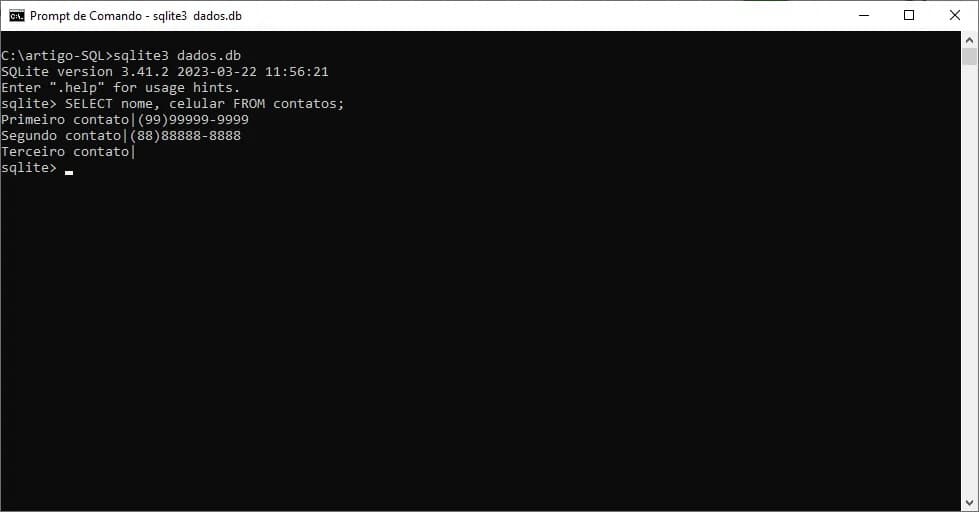
Observe que após executar o comando são exibidas três linhas contendo exatamente os dados que inserimos na seção de inserção de dados com o comando INSERT.
Perceba também que a terceira linha (identificada por “Terceiro contato” não apresentou nada após a barra de delimitação dos campos ( | ), pois, no nosso exemplo, ao inserir este registro não informamos tal dado. Veremos na seção sobre o comando UPDATE como alterar isso.
E, para o leitor mais observador, pode ter ficado claro também que a apresentação da tabela desta forma pode dificultar um pouco a identificação dos valores listados, pois, não é exibido nenhum cabeçalho para identificação das colunas.
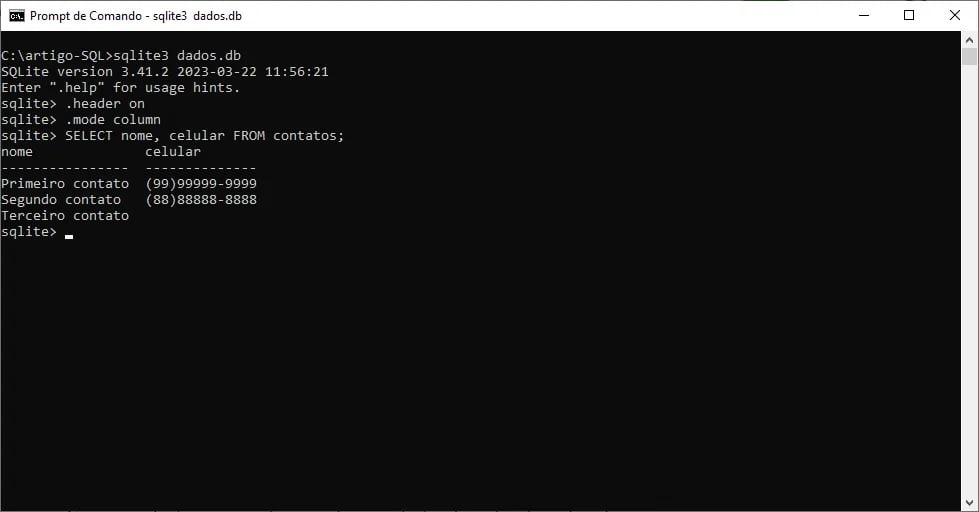
Para resolver esta questão, podemos utilizar dois comandos SQLite disponíveis. O primeiro, irá “ligar” o cabeçalho de cada coluna e o segundo irá formatar a saída de dados em colunas. No prompt de comandos do SQLite, basta digitar os seguintes (seguido de enter após cada comando):
.header on
.mode column
Após a execução dos dois comandos, pode-se refazer a consulta e o resultado apresentado será como o da imagem 06 (bem mais amigável, não é? risos)
Uma varição útil do comando SELECT para analisar todos os campos e registros de uma tabela é com o uso do caractere especial asterisco ( * ) ao invés de informar coluna-a-coluna. Veja o exemplo a seguir:
SELECT * FROM contatos;
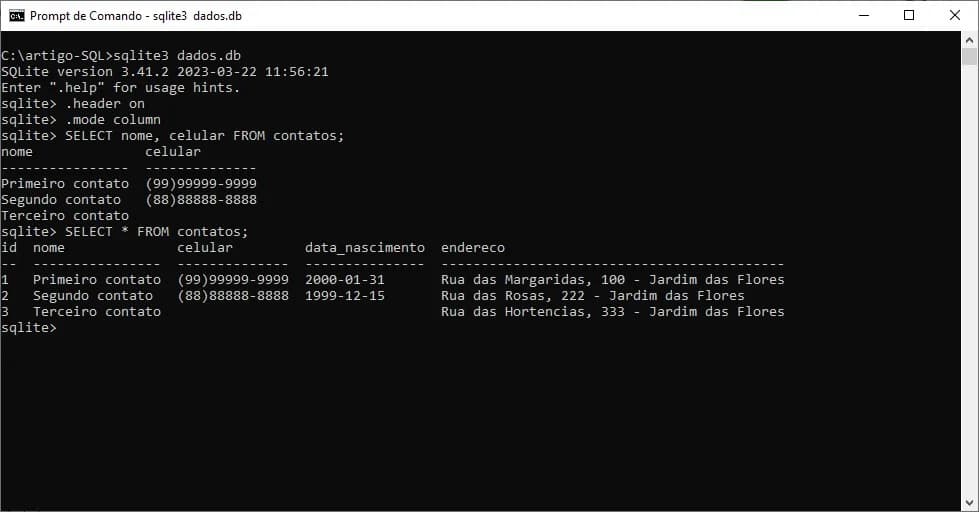
Quando queremos visualizar todos os campos de uma tabela, utilizamos o asterisco como alternativa a listagem dos nomes de cada coluna.
Neste ponto, vai uma dica para quem trabalha com muitos dados e tabelas com muitos campos: quando não informa os campos que deseja realmente visualizar pode ocorrer lentidão na recuperação dos dados. Então, use o asterisco apenas em análises exploratórias de dados e em ambiente de desenvolvimento. É uma boa prática sempre deixar explícito no comando SELECT as colunas que deseja realmente recuperar os dados.
Outra variação útil ao executar o comando SELECT é a possibilidade de ordenação dos valores de um ou mais campos (seja ordenação ascendente ou descendente).
Para ordernar o resultado de uma consulta, independente da ordem que foi inserido o registro no banco de dados, basta utilizar a cláusula ORDER BY.
Antes porém, para ilustrar um pouco melhor, vou inserir um outro registro de contato e só depois executaremos o comando SELECT ordenando os registros.
O comando para inserção do novo registro é o seguinte:
/* Inclusão de novo contato */
INSERT INTO contatos (id, nome)
VALUES (4, 'Ana Joaquina Pereira dos Santos');
Agora, veja no exemplo como fazer para recuperar os registros de forma ordenada:
/* Seleção dos contatos ordenando por nome */
SELECT * FROM contatos ORDER BY nome ASC;
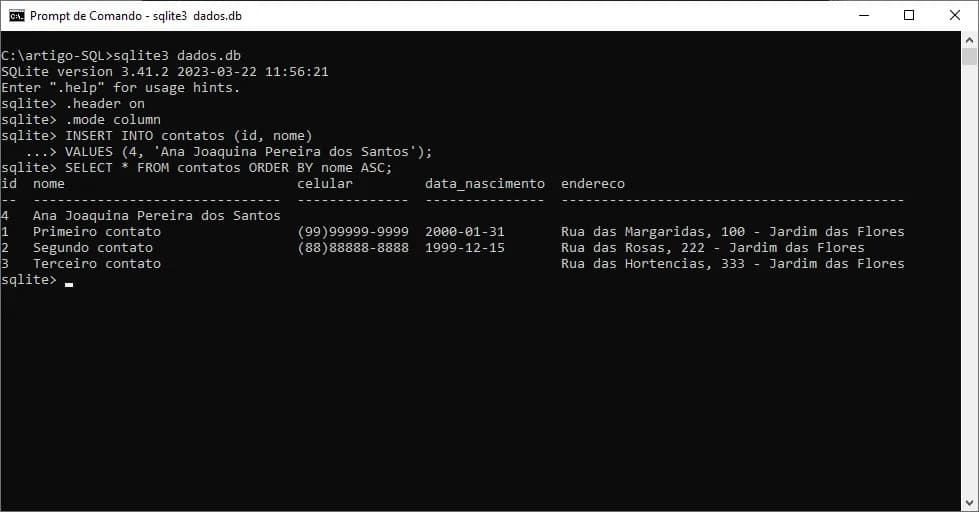
O resultado obtido foi uma consulta ordenando o campo nome de forma ascendente (ou seja, de A a Z). Perceba que mesmo o registro com o nome Ana ter sido incluído por último, no resultado de nossa consulta, ele foi o primeiro a ser recuperado após a ordenação dos dados.
No quadro abaixo, podemos ver em detalhes cada uma das partes que compõem a cláusula ORDER BY.
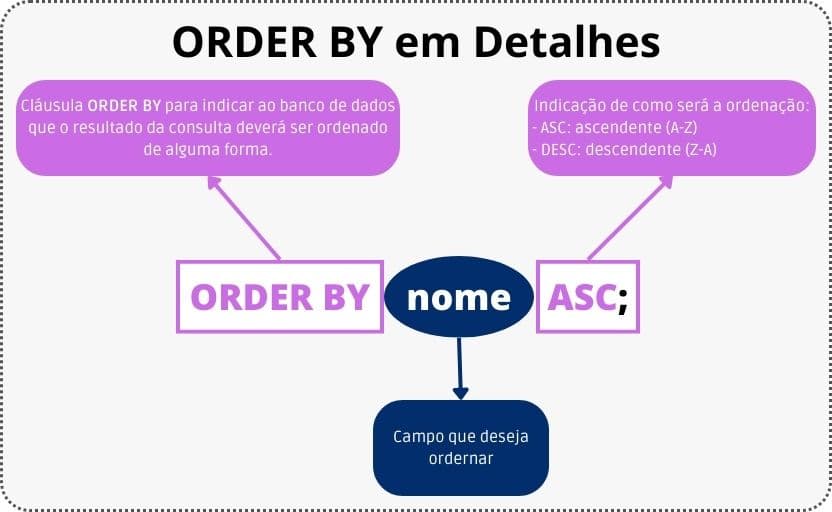
Como citado na sintaxe do comando SELECT, a cláusula ORDER BY aceita vários campos. Para passar mais de um campo, basta separar cada um por vírgula colocando como deseja que cada campo seja ordenado.
Veja um exemplo de ordenação com os campos data_nascimento e nome:
SELECT * FROM contatos
ORDER BY data_nascimento ASC, nome ASC;
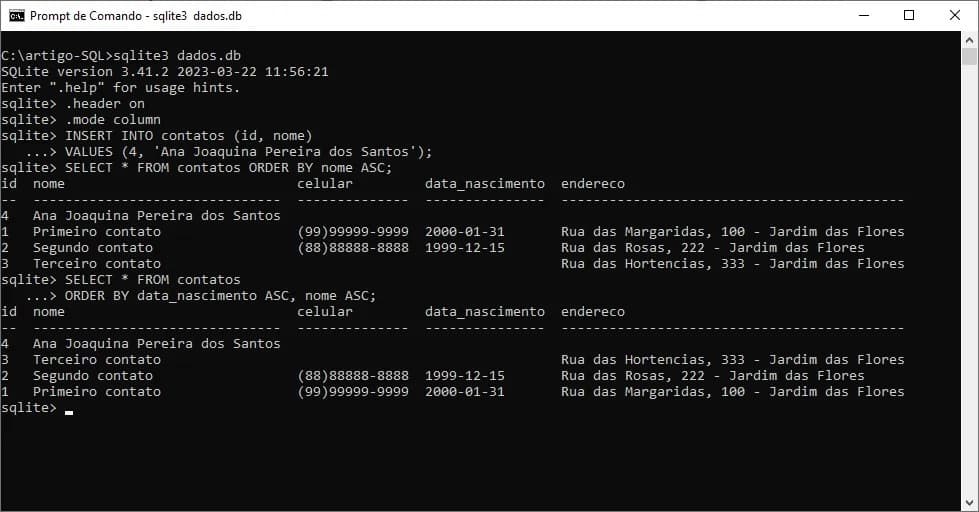
O resultado, conforme apresentado na imagem 09 corresponde a ordenação de data_nascimento e posteriormente nome do contato.
O leitor pode se perguntar: “Mas a Ana permaneceu em primeiro no resultado e não tem data de nascimento salvo no registro dela. Como isso é possível?”
Como não há nada (vazio) no campo data_nascimento tanto para Ana quanto para o Terceiro contato, ambos, no SQLite ficam ordenados antes dos demais registros. Em alguns SGBD’s quando não há um valor de data em campos deste tipo, o valor salvo é null e, nesta situação, a ordenação pode ficar diferente. Mas cabe o teste, consultar a documentação do SGBD e a forma mais adequada para recuperação dos dados.
Podemos perceber claramente que, o resultado apresenta primeiramente ordenação por data de nascimento e, depois ordena pelo campo nome (por isso o Segundo contato apareceu antes do Primeiro contato).
Para não extender ainda mais este artigo (que já está bastante longo, risos), apresentarei apenas mais três exemplos utilizando a cláusula WHERE (também utilizada nos comandos UPDATE e DELETE que veremos a seguir).
Para entender a cláusula WHERE, podemos associá-la diretamente a um filtro.
Como percebemos nos exemplos apresentados até agora, todos os registros da tabela contatos foram retornados em nossas consultas (independente de utilizarmos dois campos, como no primeiro exemplo, ou quando utilizamos todos os campos ao substituir o nome das colunas a serem retornadas por asterisco).
Após a cláusula WHERE vem justamente a condição que desejamos filtrar. Essa condição pode ser composta por um ou vários campos. Vejamos o primeiro exemplo:
Suponha que eu desejo consultar na minha tabela contatos, todos os contatos com a id igual a 4. Veja como fica o comando:
SELECT * FROM contatos WHERE id = 4;
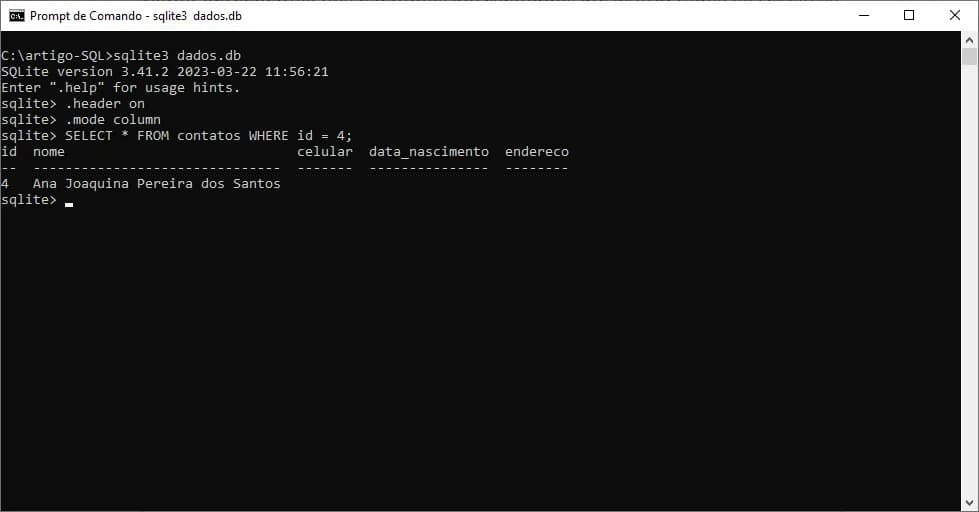
Veja que o resultado obtido ao incluir a cláusula WHERE agora mudou. Obtemos apenas um registro como resultado (justamente porque o campo id é PRIMARY KEY e não pode ser duplicado). Isso quer dizer que, o resultado obtido pela consulta SQL foi “filtrado” retornando apenas os registros que correspondem a condição imposta (id = 4).
A condição segue a ordem booleana para obtenção dos resultados. Para maiores informações sobre esse tipo de condição, faça uma pesquisa por “tabela verdade” e “combinações booleanas” no seu buscador preferido.
Como outra forma de exemplificar, vamos agora, consultar em nossa tabela contatos, todos os registros que tenham, em alguma parte do nome a palavra “contato”. O comando para retornar tal resultado é:
SELECT * FROM contatos
WHERE nome LIKE '%contato%';
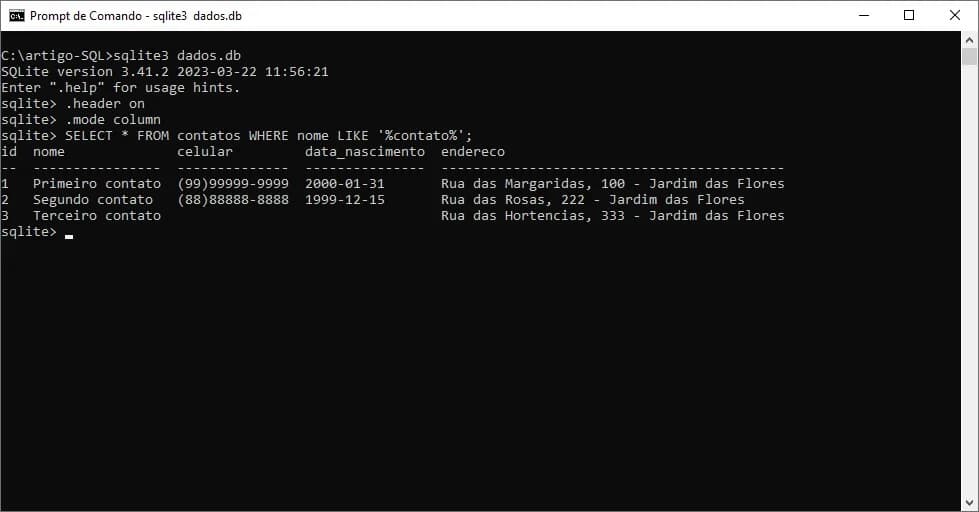
Neste exemplo, filtramos todos os contatos cujo nome tenham em qualquer parte do campo a palavra “contato”. Para isso, utilizamos o operador LIKE que, busca por padrões em uma cadeia de caracteres.
Além do operador, delimitamos o que buscamos por dois caracteres que chamamos de curinga (%). Como a palavra buscada ficou entre os caracteres curingas (‘%contato%’), o resultado obtido será todas as linhas que em qualquer parte do campo nome tenham a palavra contato.
Se por exemplo, ao invés de delimitarmos a palavra buscada, como no exemplo por curingas e, apenas colocássemos em uma das partes, o resultado seria diferente. Na forma apresentada no exemplo, o comando busca por qualquer caractere antes ou depois da palavra “contato”.
Se o curinga estivesse apenas antes da palavra “contato”, o comando retornaria apenas os registros que terminassem com a palavra “contato” (excluindo, neste caso, qualquer registro que possua a palavra contato em outra parte que não no final).
O contrário também apresenta resultado diferente: ao incluir o caractere curinga apenas após a palavra buscada, o resultado seriam apenas os registros que o campo nome iniciasse com a palavra “contato”.
Apesar de parecer um pouco confuso, com o tempo e prática tudo começa a fazer mais sentido.
Como exercício, inclua mais registros em sua tabela utilizando alguma palavra (ou nome) específica em vários registros e em partes diferentes (no início, no meio e no final) e execute os comandos utilizando as variações com o caractere curinga % conforme apresentado no exemplo a seguir:
/* Consulta delimitando palavra buscada por caractere curinga % */
SELECT * FROM contatos WHERE nome LIKE '%<COLOQUE AQUI A PALAVRA BUSCADA>%';
/* Consulta buscando por palavra que esteja no início do campo */
SELECT * FROM contatos WHERE nome LIKE '<COLOQUE AQUI A PALAVRA BUSCADA>%';
/* Consulta buscando por palavra que esteja no final do campo */
SELECT * FROM contatos WHERE nome LIKE '%<COLOQUE AQUI A PALAVRA BUSCADA>';
Por fim, nosso último exemplo de SELECT será utilizando o operador lógico AND.
Quando queremos utilizar mais que um campo nas condições da cláusula WHERE podemos utilizar os operadores lógicos (para mais informações, consulte por “operadores lógicos”).
Vou apresentar a utilização do operador AND mas não limite-se a este exemplo. Busque pesquisar variações e aprofunde-se na utilização dos operadores, pois, são utilizados em muitos casos no dia-a-dia de trabalho.
Para exemplificar o uso do operador AND, vou criar outra tabela denominada produtos com os seguintes campos:
- id: do tipo numérico e também identificador único (PRIMARY KEY)
- descricao: do tipo texto
- preco: do tipo real (número com ponto flutuante)
- categoria: do tipo texto
- estoque: do tipo numérico
E após a criação vou inserir alguns registros para apresentar depois o resultado de consultas utilizando o operador AND. Não vou explicar detalhadamente o processo de criação e inclusão de dados para esta nova tabela (pois já fizemos isso anteriormente). Mas deixo os comandos aqui para quem quiser fazer a experiência e acompanhar o restante do artigo.
/* Criação da tabela produtos */
CREATE TABLE produtos (
id INTEGER PRIMARY KEY,
descricao TEXT,
preco DOUBLE,
categoria TEXT,
estoque INTEGER
);
/* Inserção de dados na tabela produtos */
INSERT INTO produtos VALUES(1, 'Bolacha Recheada', 3.49, 'FARINACEOS', 15);
INSERT INTO produtos VALUES(2, 'Biscoito de Polvilho', 2.29, 'FARINACEOS', 11);
INSERT INTO produtos VALUES(3, 'Arroz Gostoso', 19.50, 'CESTA BASICA', 50);
INSERT INTO produtos VALUES(4, 'Feijao Carioca', 7.79, 'CESTA BASICA', 0);
INSERT INTO produtos VALUES(5, 'Cerveja Gelada', 8.40, 'BEBIDAS', 20);
INSERT INTO produtos VALUES(6, 'Refrigerante Gelado', 5, 'BEBIDAS', 32);
INSERT INTO produtos VALUES(7, 'Suco de Goiaba', 7.80, 'BEBIDAS', 18);
INSERT INTO produtos VALUES(8, 'Leite Tetrapak', 4.49, 'CESTA BÁSICA', 28);
INSERT INTO produtos VALUES(9, 'Suco de Laranja', 19.50, 'BEBIDAS', 0);
INSERT INTO produtos VALUES(10, 'Farinha de Trigo Integral', 7.79, 'FARINACEOS', 0);
O resultado após a criação e inserção dos dados na tabela produtos está apresentado na imagem 12:
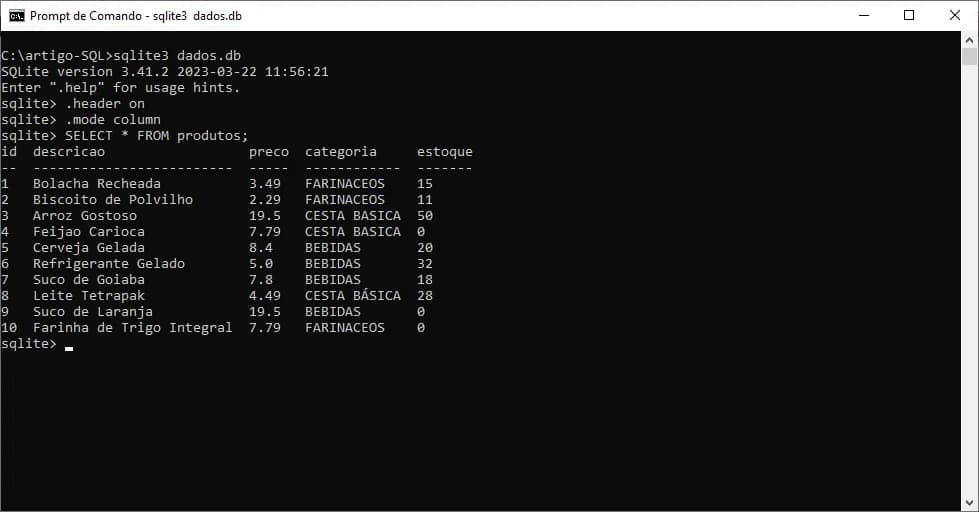
Agora vamos ao nosso exemplo, imagine que esse banco de dados seja de uma mercearia e, que o gerente queira visualizar todos os produtos de determinada categoria que estão com quantidade maior que 0 no estoque. Vamos pegar como exemplo, a categoria “BEBIDAS”. O comando para realizar tal consulta seria:
SELECT * FROM produtos
WHERE categoria='BEBIDAS' AND estoque>0;
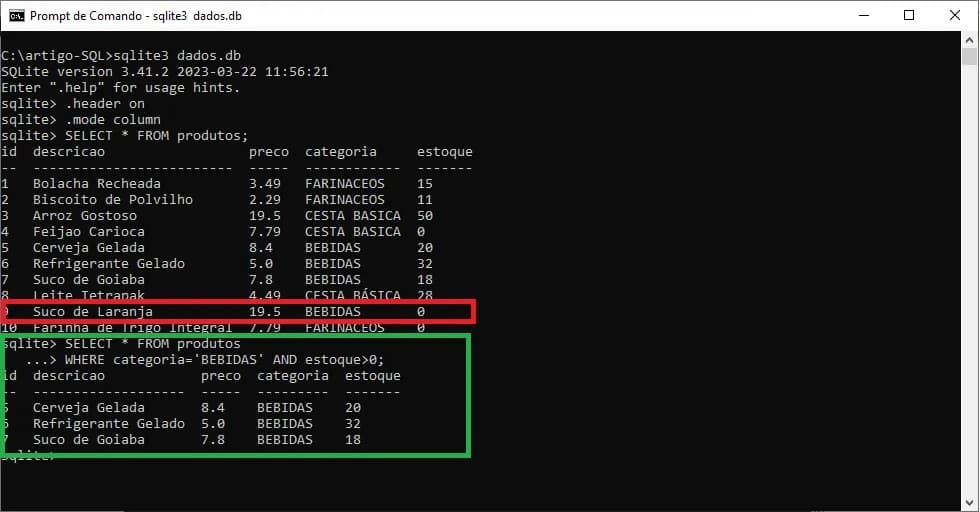
Em verde, o resultado da consulta listada acima. Observe que o produto em vermelho (Suco de Laranja) não apareceu no resultado quando utilizamos o operador AND. Mesmo que o produto pertença neste caso, a categoria filtrada (“BEBIDAS”), ele não atende ao critério da segunda condição: ter valor superior a 0 no campo estoque.
Teste variações do comando SELECT utilizando o operador AND e outros operadores. Além disso, tente buscar por outros valores diferentes dos que citei aqui e observe os resultados apresentados. Quanto mais você treinar e testar, melhor será seu desempenho no mercado de trabalho.
Na próxima seção apresento o comando UPDATE e alguns exemplos para atualizar os dados inseridos nas tabelas que criamos até aqui.
Como alterar um registro já inserido no banco de dados
Como já citado, para alterar um registro em uma tabela de um banco de dados relacional utilizamos o comando UPDATE.
A sintaxe para o comando UPDATE é:
UPDATE nome_da_tabela
SET nome_da_coluna_1 = valor_da_coluna_1, nome_da_coluna_2 = valor_da_coluna_2, ...
[ WHERE condição ];
Onde:
nome_da_tabela: é o nome da tabela que será atualizadanome_da_coluna_i: é o nome da coluna que será atualizada (que pode ser uma ou mais colunas)valor_da_coluna_i: é o novo valor que será atribuído à colunacondição: é uma condição que determina quais linhas serão atualizadas. Se omitida, todas as linhas da tabela serão atualizadas.
Utilizando nossa tabela contatos como exemplo, digamos que, o terceiro contato precisa de ser atualizado com as seguintes informações:
- Coluna nome: Paulo
- Coluna celular: (77)77777–7777
- Condição: id = 3
O comando para atualização das colunas nome e celular utilizando como condição o id igual a 3 é:
UPDATE contatos
SET nome = 'Paulo', celular = '(77)77777-7777'
WHERE id = 3;
Se tudo estiver correto, o comando será executado e nenhuma mensagem de erro será exibida (conforme imagem 14).
Realizando uma consulta com o comando SELECT, observe como ficou nossa tabela de contatos após a atualização:
SELECT * FROM contatos;
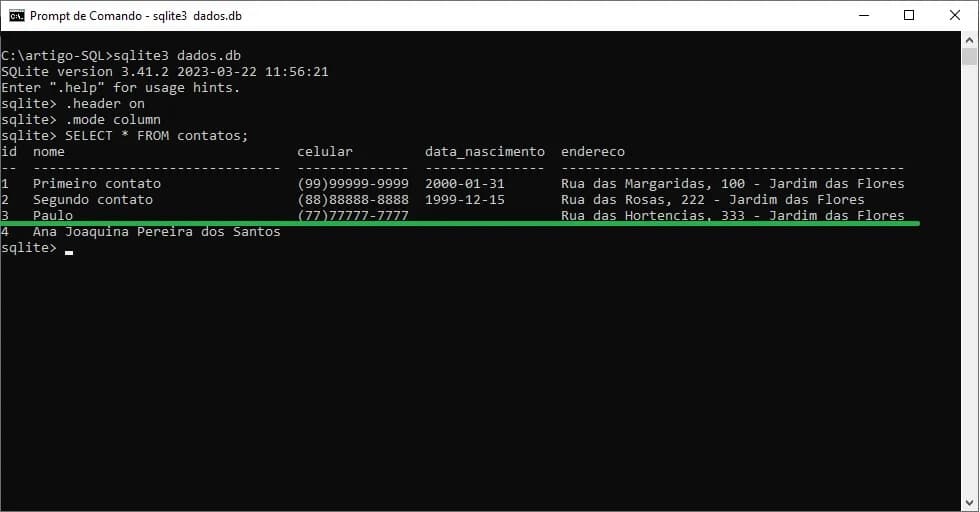
Sobre a condição (parâmetro informado após a cláusula WHERE) é muitíssimo importante adicionar tal valor para garantir que a alteração ocorra apenas no(s) registro(s) desejado(s).
Uma dica importante sobre o uso da cláusula WHERE no comando UPDATE é: sempre inicie seus scripts de UPDATE pela cláusula WHERE. Isso irá garantir que o comando executado não afetará registros indesejados.
Embora no exemplo, o alvo da atualização fosse apenas o registro onde o id é igual a 3, nada impede que vários registros sejam atualizados de uma única vez.
Por exemplo, imagine que você deseje atualizar um grupo de produtos na tabela de produtos aplicando um reajuste de 10% no campo preco. O comando para realizar tal alteração será:
UPDATE produtos SET preco=preco*1.10
WHERE categoria = 'BEBIDAS';
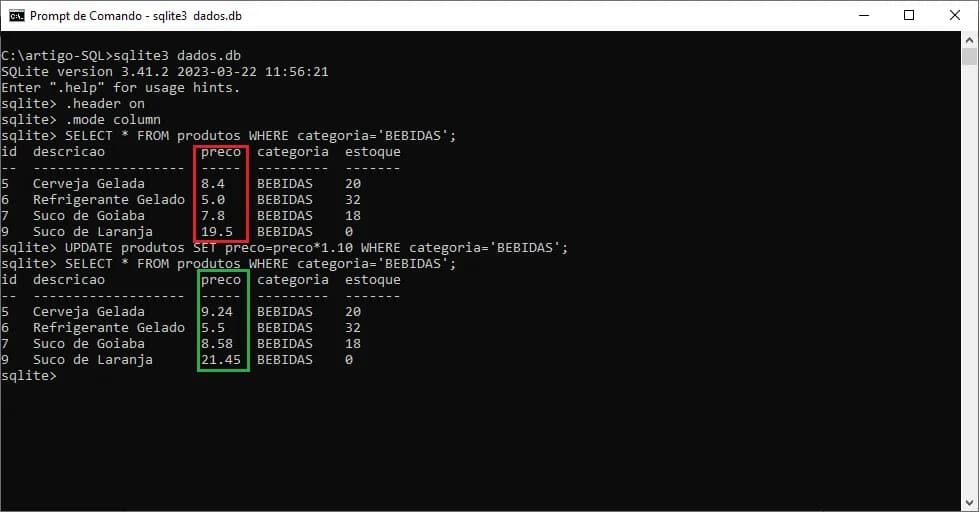
Observe os destaques em vermelho e verde. O preço destacado em vermelho apresenta o valor como inserido e, a coluna destacada em verde após a atualização de preço de 10%.
Um destaque para o comando que acabamos de executar é com relação ao trecho: preco=preco*1.10. Se você se perguntou sobre a possibilidade de realizar operações matemáticas nos comandos SQL, a resposta é um grande SIM. Neste caso, para reajustar o valor do campo preco, estou multiplicando o valor atual do campo por 1.10 (ou seja, 110%).
Para maiores detalhes sobre os operadores matemáticos aceitos por cada SGBD, recomendo a leitura da documentação oficial do desenvolvedor.
Neste ponto é importante explicar algo que talvez tenha passado despercebido durante a leitura: a importância do campo id (neste artigo determinado como PRIMARY KEY — ou chave primária).
Este tipo de campo desempenha funções muito importantes nas tabelas. Uma delas, que já verificamos durante a seção de inserção dos dados é garantir que os registros não sejam duplicados.
Já na atualização e consulta de dados, ele otimizará o processo, pois trata-se de um campo indexado no banco de dados. No futuro, posso também escrever um artigo sobre indexação, pois é um assunto muito amplo para tratarmos aqui.
Da mesma forma que foi apresentado o uso da cláusula WHERE para o comando SELECT, é possível utilizar no comando UPDATE. Teste as variações e me escreva sobre o que pode observar de diferente 🙂 .
Como apagar um registro de uma tabela
Para finalizar nossa lista de comandos DML, apresento a seguir o comando DELETE, utilizado para apagar registros de uma ou mais tabelas.
A sintaxe para o comando DELETE é a seguinte:
DELETE FROM nome_da_tabela WHERE condição;
Onde:
nome_da_tabela: é o nome da tabela que será afetada pela operação DELETE;condição: é a condição que determina quais registros serão excluídos da tabela. ATENÇÃO: se essa condição for omitida, todos os registros da tabela serão excluídos. A recomendação feita na seção sobre o comando UPDATE é válida aqui também: inicie toda operação de DELETE pela cláusula WHERE.
Por exemplo, se quisermos excluir todos os contatos da nossa tabela que tenham no nome a palavra ‘contato’, podemos usar o seguinte comando:
DELETE FROM contatos WHERE nome LIKE '%contato%';
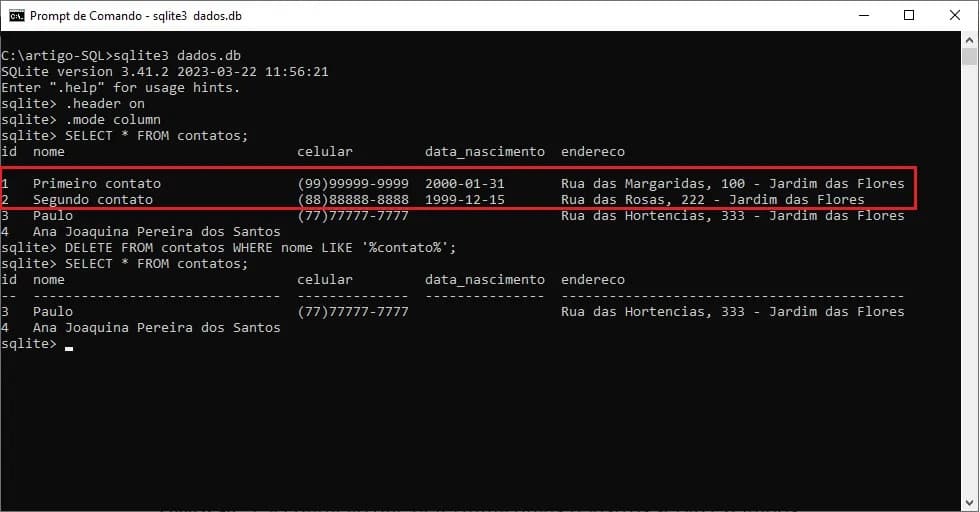
Em nosso exemplo, eu optei por excluir utilizando o campo nome, para justamente, apresentar a exclusão de vários registros.
Mas poderia ser utilizado (e recomendo) a chave primária da tabela contatos (no caso o campo id).
Observe na imagem 17 o resultado de uma consulta antes (em vermelho) e depois da execução do comando DELETE. Perceba que foram excluídos os contatos com os nomes “Primeiro contato” e “Segundo contato”.
As possibilidades para a cláusula WHERE, assim como nos comandos SELECT e UPDATE são válidas para o comando DELETE. Portanto, explore todas as possibilidades que imaginar.
Considerações Finais
No artigo anterior eu citei que tinha ficado maior do que o esperado. Este então, nem se fala (risos). Assim como no anterior a este, era necessário não fragmentar este conteúdo.
Claro que o apresentado aqui é o resumo do resumo. Existem muitas outras possibilidades e variações. E até partes que, já durante o texto eu citei ser matéria para um artigo “solo” (ou série de artigos).
Os exemplos disponibilizados para cada comando são de níveis básicos. A minha recomendação é: utilize o conhecimento adquirido até aqui para pesquisar mais e mais. Não limite-se ao que escrevi.
Uma última consideração é, sempre lembrar que os comandos do grupo DML são utilizados para manipular os dados: seja inserindo, alterando, consultando ou excluindo.
Por fim, gostaria de agradecer a você que chegou até aqui comigo. Minhas redes sociais estão abertas para conversamos e esclarecer dúvidas. Aceito sugestões para novos artigos e também, se tem algo que informei nesta série de artigos incorretamente, ficarei muito feliz em corrigir e adicionar o colaborador da correção.
Fiquem de olhos nas minhas redes sociais e acompanhem por aqui e pelo Medium para não perder os próximos artigos.
Até o próximo!
—
Artigo publicado originalmente na plataforma Medium em 29 de abril de 2023. O acesso ao artigo original pode ser realizado aqui.
Referências
Sistemas de banco de dados / Ramez Elmasri e Shamkant B. Navathe, 4ª Edição, 2009, Editora Pearson Addison Wesley;
Database Design for Mere Mortals: A Hands-On Guide to Relational Database Design / Michael J. Hernandez, 3ª Edição, 2021, Editora Addison-Wesley Professional
SQLite: https://sqlite.org/index.html, acessado em 04/04/2023 às 8h37.

Sobre o autor
Paulo Fernando Abse Benassi é formado em Sistemas de Informação pela Libertas – Faculdades Integradas de São Sebastião do Paraíso/MG. Analista de Sistemas, desenvolvedor web e analista de dados. Trabalha na área de tecnologia desde 2003. Desde o início da carreira, começou a estudar sobre a área tecnológica e nunca mais parou. Em aprendizado contínuo. Clique aqui para analisar os projetos e atividades desempenhadas pelo autor.
Artigos relacionados


